分布式服务框架设计
列了一些设计分布式系统时需要考虑的问题,欢迎讨论。
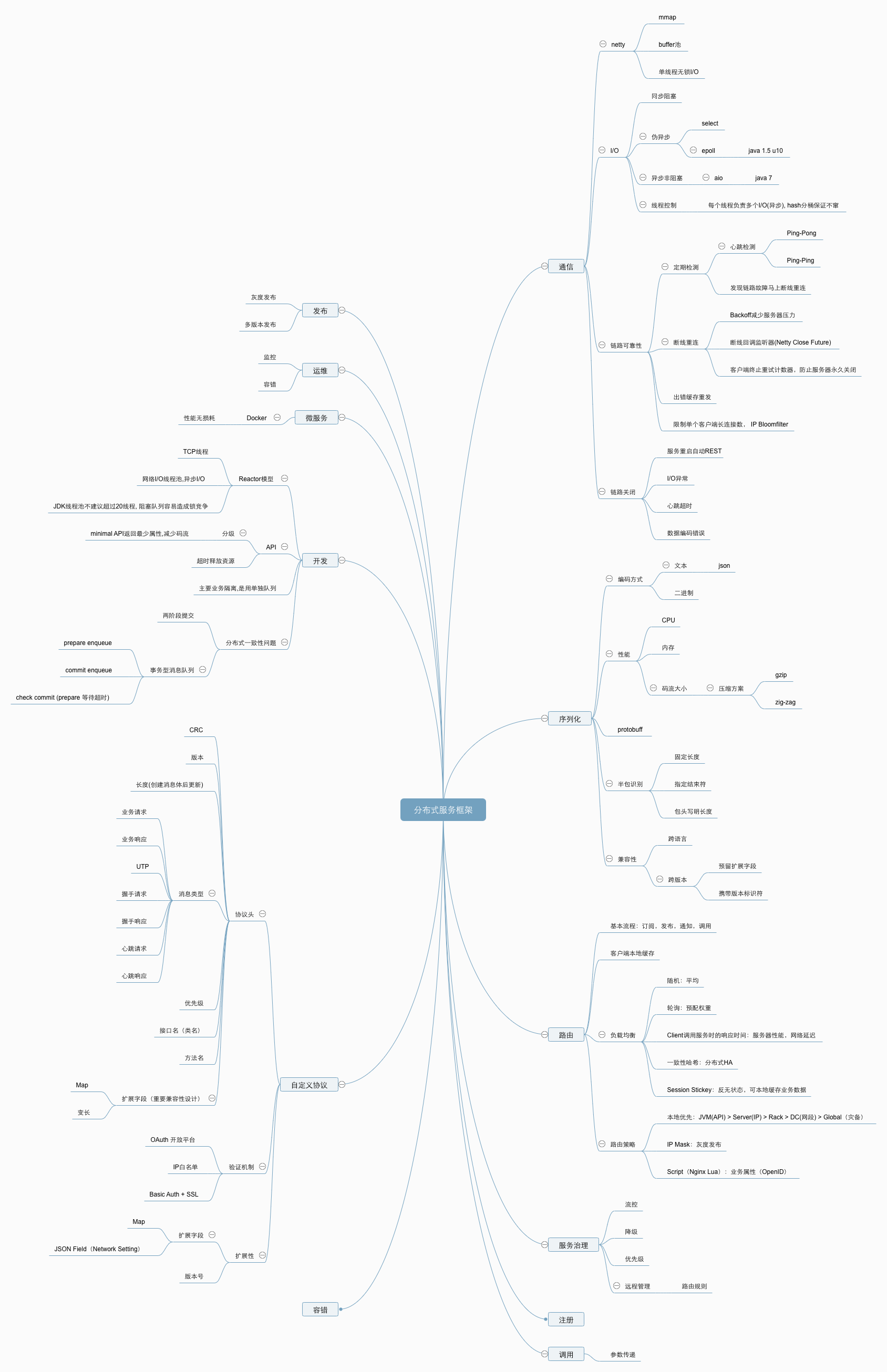
列了一些设计分布式系统时需要考虑的问题,欢迎讨论。

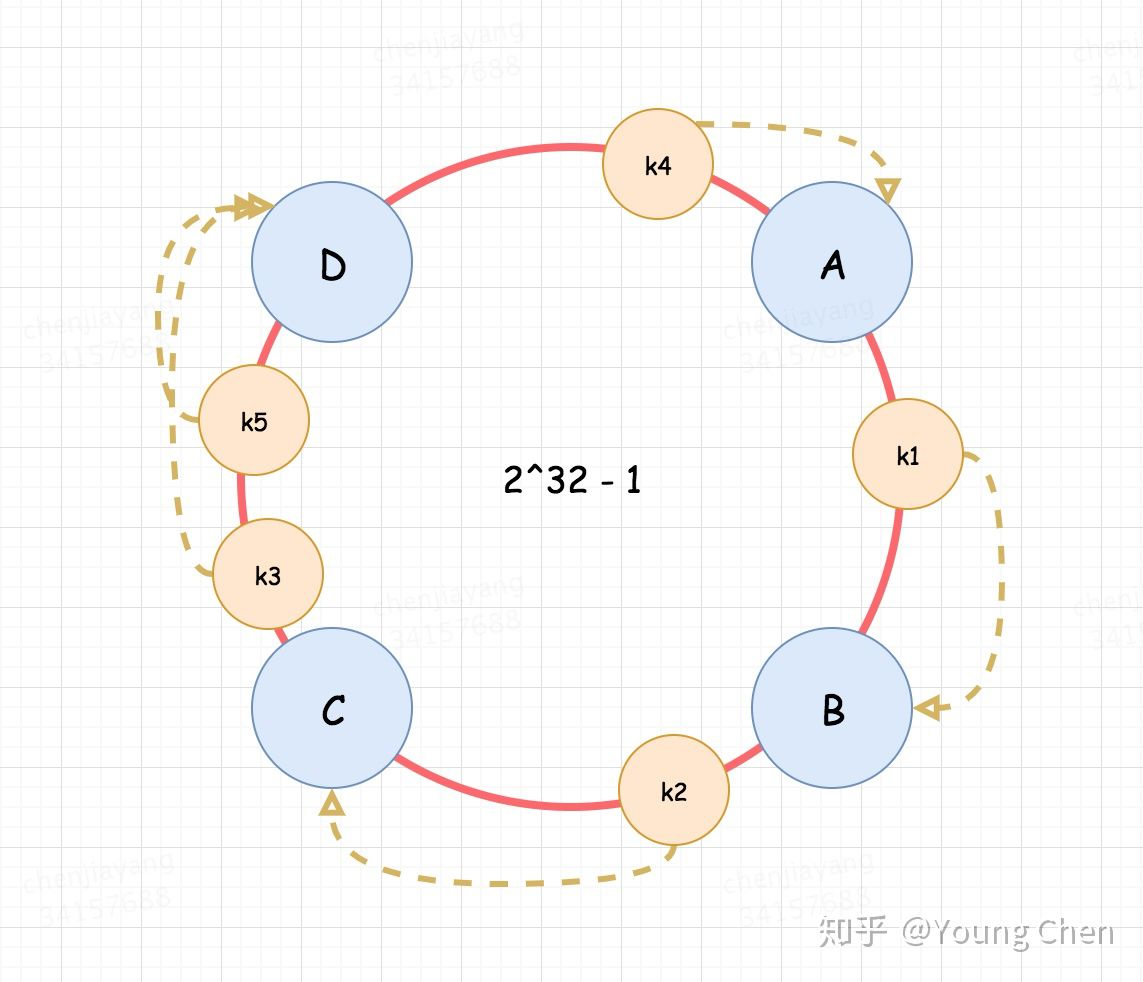
Dynamo是亚马逊上线多年的分布式数据库。随着不断的版本迭代,逐步满足了互联网场景的各种苛刻要求,也实践了近几十年来产生的多种经典理论。可谓集十八般武艺于一身啊。。。 重读 Amazon Dynamo 论文有感 下文转自知乎,原作者陈蔚澜:https://zhuanlan.zhihu.com/p/98640498 本文内容不仅仅局限于 Dynamo 什么是 Dynamo 亚马逊在业务发展期间面临一些问题,主要受限于关系型数据库的可扩展性和高可用性,希望研发一套新的、基于 KV 存储模型的数据库,将之命名为 Dynamo。 相较于传统的关系型数据库 MySQL,Dynamo 的功能目标与之有一些细小的差别,例如 Amazon 的业务场景多数情况并不需要支持复杂查询,却要求必要的单节点故障容错性、数据最终一致性(即牺牲数据强一致优先保障可用性)、较强的可扩展性等。 可以肯定的是,在上述功能目标的驱使下,Dynamo 需要解决以下几个关键问题: Dynamo 和 MySQL 的关系? 有的人有这种疑问,其实二者没有什么关系,Dynamo 叙述的是一种 NoSQL 数据库的设计思想和实现方案,它是一个由多节点实例组成的集群,其中一个节点称之为 Instance(或者 Node 其实无所谓),这个节点由三个模块组成,分别是请求协调器、Gossip 协议检测、本地持久化引擎,其中最后一个持久化引擎被设计为可插拔的形式,可以支持不同的存储介质,例如 BDB、MySQL 等。 数据分片 数据分片的实现方式 数据分片实在是太常见了,因为海量数据无法仅存储在单一节点上,必须要按照某种规则进行划分之后分开存储,在 MySQL 中也有分库分表方案,它本质上就是一种数据分片。 数据分片的逻辑既可以实现在客户端,也可以实现在 Proxy 层,取决于你的架构如何设计,传统的数据库中间件大多将分片逻辑实现在客户端,通过改写物理 SQL 访问不同的 MySQL 库;而 NewSQL 数据库倡导的计算存储分离架构中呢,通常将分片逻辑实现在计算层,即 Proxy 层,通过无状态的计算节点转发用户请求到正确的存储节点。 Redis 集群的数据分片 Redis 集群也是 NoSQL 数据库,它是怎么解决哈希映射问题的呢?它启动时就划分好了 16384 个桶,然后再将这些桶分配给节点占有,数据是固定地往这 16384 个桶里放,至于节点的增减操作,那就是某些桶的重新分配,缩小了数据流动的范围。 Dynamo 的数据分片 Dynamo 设计之初就考虑到要支持增量扩展,因为节点的增减必须具备很好的可扩展性,尽可能降低期间的数据流动,从而减轻集群的性能抖动。Dynamo 选择采用一致性哈希算法来处理节点的增删,一致性哈希的算法原理细节这里不再赘述,只是提一下为什么一致性哈希能解决传统哈希的问题。 我们想象一下传统哈希算法的局限是什么,一旦我给定了节点总数 h,那数据划分到哪个节点就固定了(x mod h),此时我一旦增减 h 的大小,那么全部数据的映射关系都要发生改变,解决办法只能是进行数据迁移,但是一致性哈希可以在一个圆环上优先划分好每个节点负责的数据区域。这样每次增删节点,影响的范围就被局限在一小部分数据。 下图蓝色小圆 ABCD 的代表四个实际节点,橙色的小圆代表数据,他们顺时针落在第一个碰到的节点上 一致性哈希的改进 Read more
0 Comments